Posted in 2020
Dask jobqueue on Levante
- 16 November 2020
According to the official Web site, Dask jobqueue can be used to
deploy Dask on job queuing systems like PBS, Slurm, MOAB, SGE,
LSF, and HTCondor. Since the queuing system on Levante is Slurm, we are
going to show how to start a Dask cluster there. The idea is simple as
described here. The difference is that the workers can be distributed
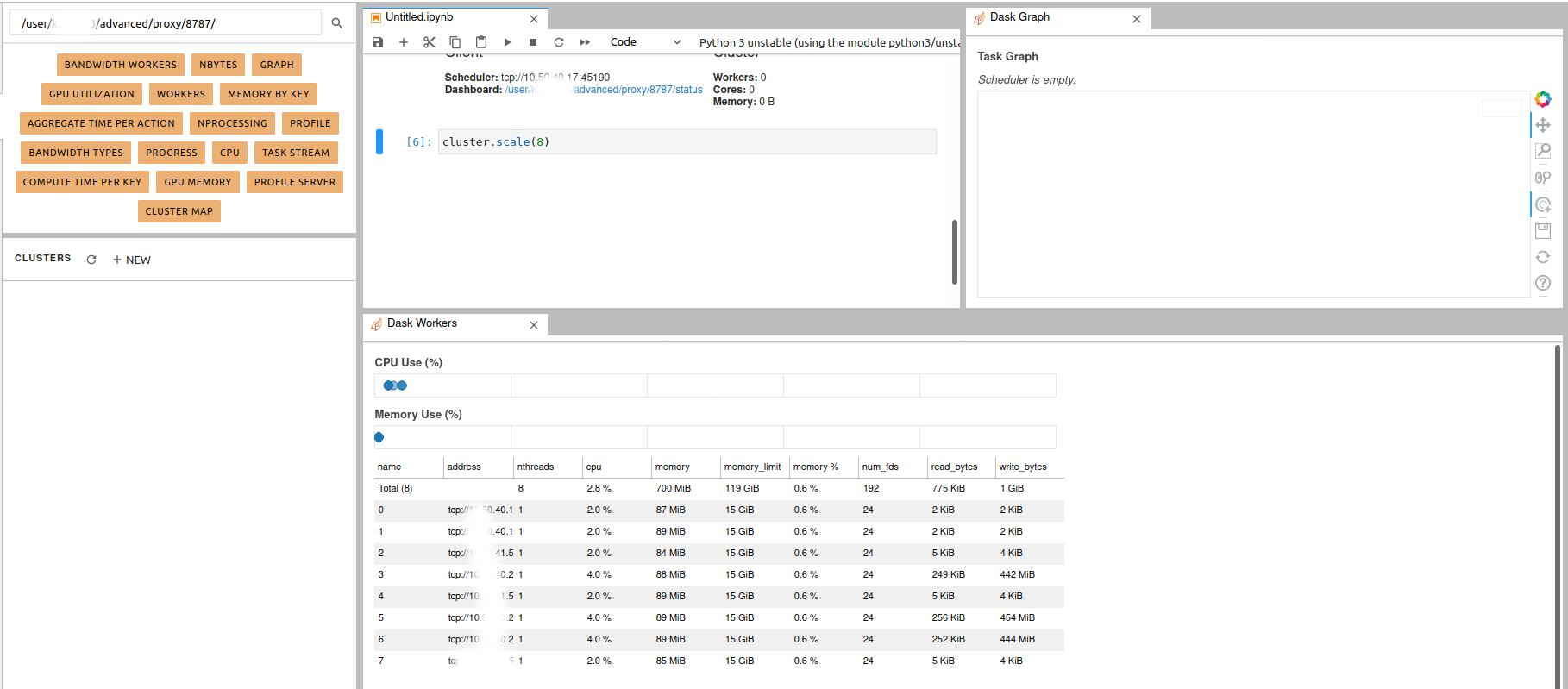
through multiple nodes from the same partition. Using Dask jobqueue you can launch
Dask cluster/workers as a Slurm jobs. In this case, Jupyterhub will play an interface role and the Dask
can use more than the allocated resources to your jupyterhub session
(profiles).
Load the required clients
Enable NCL Kernel in Jupyterhub
- 05 November 2020
Can’t use NCL (Python) as kernel in Jupyter
This tutorial won’t work
FileNotFoundError: [Errno 2] No such file or directory
- 07 October 2020
See Wrapper packages here.
you:
Jupyterhub log file
- 25 September 2020
Each Jupyter notebook is running as a SLUM job on Levante. By default,
stdout and stderr of the SLURM batch job that is spawned by
Jupyterhub is written to your HOME directory on the HPC system. In
order to make it simple to locate the log file:
if you use the preset options form: the log file is named
jupyterhub_slurmspawner_preset_<id>.log.
Simple Dask clusters in Jupyterhub
- 18 September 2020
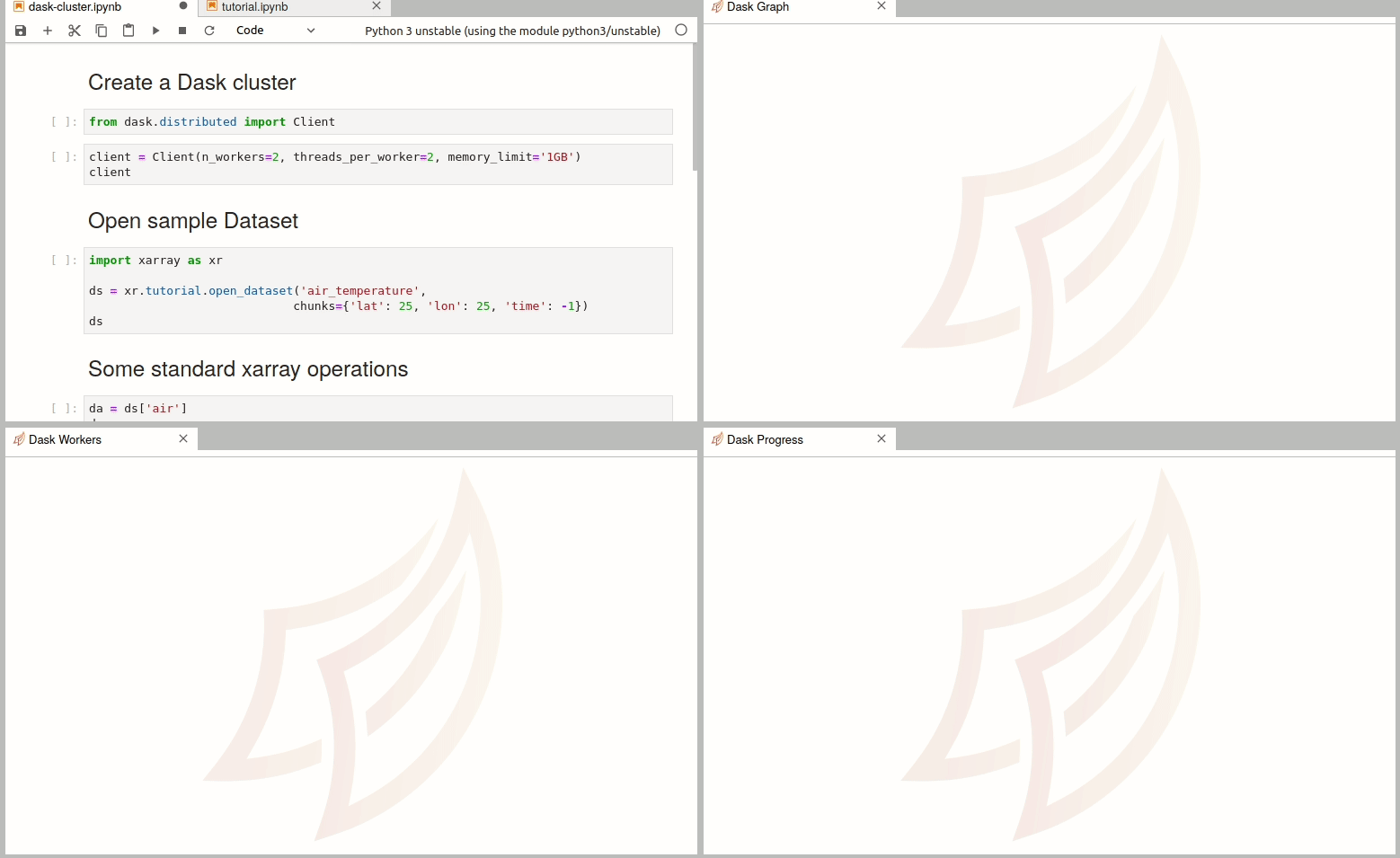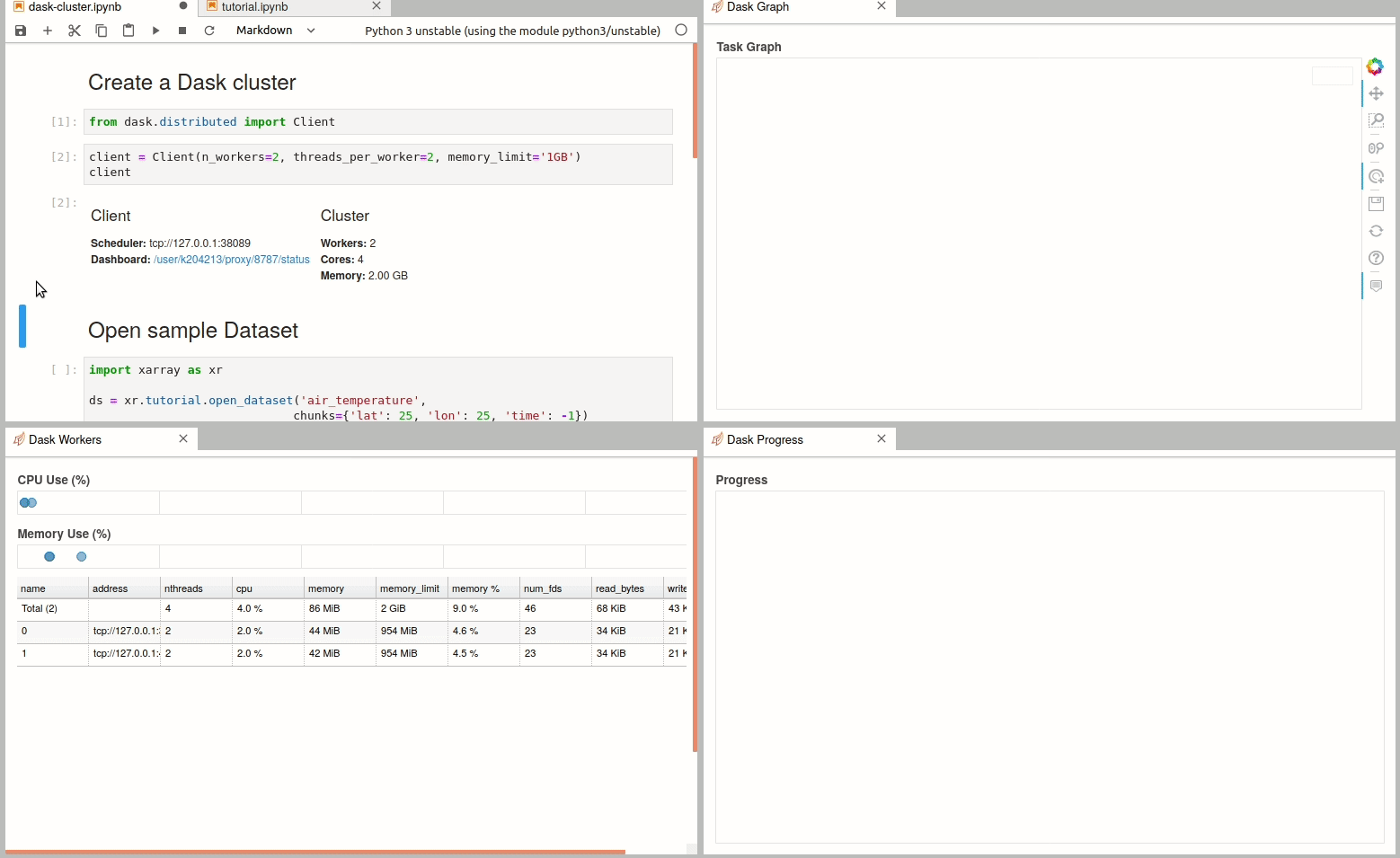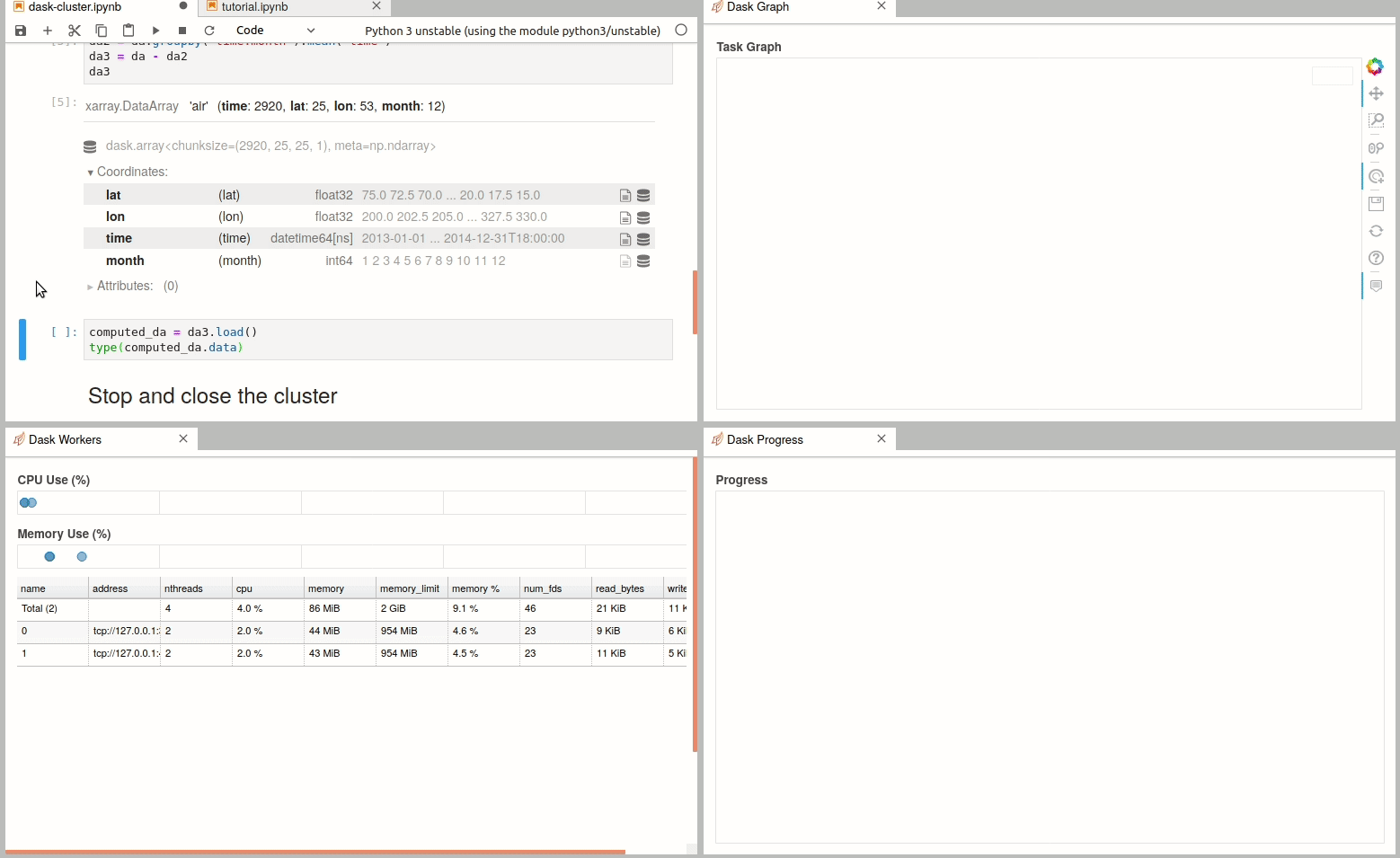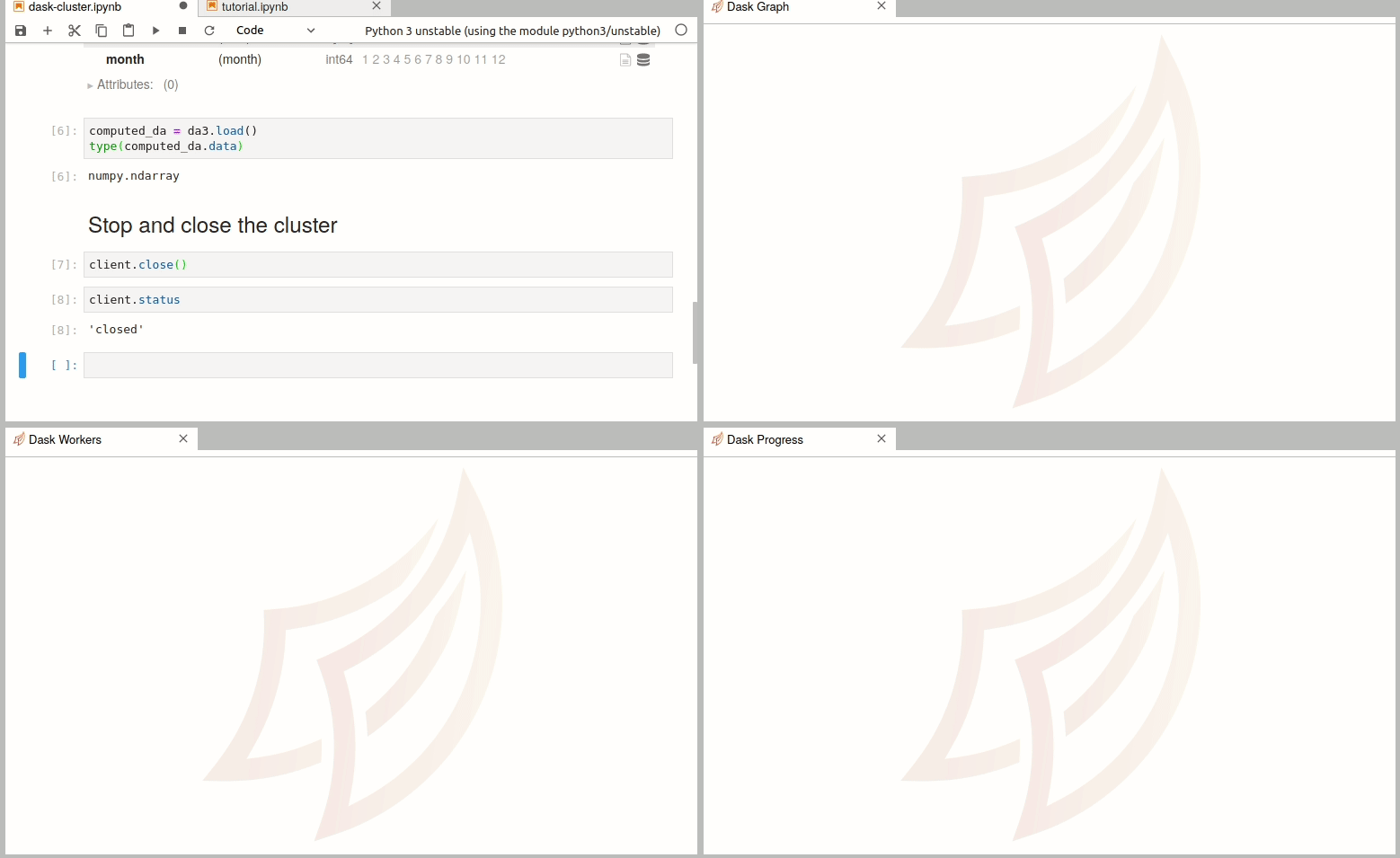
There are multiple ways to create a dask cluster, the following is only an example. Please consult the official documentation. The Dask library is installed and can be found in any of the python3 kernels in jupyterhub. Of course, you can use your own python environment.
The simplest way to create a Dask cluster is to use the distributed module:
DKRZ Tech Talks
- 03 September 2020
It is our great pleasure to introduce the DKRZ Tech Talks. In this series of virtual talks we will present services of DKRZ and provide a forum for questions and answers. They will cover technical aspects of the use of our compute systems as well as procedures such as compute time applications and different teams relevant to DKRZ such as our machine learning specialists. The talks will be recorded and uploaded afterwards for further reference.
Go here for more information.
New Jupyterhub server at DKRZ
- 03 September 2020
On August 20th, 2020 we deployed a new Jupyterhub server at the DKRZ. The new release has various new features that enhance the user experience.