All Posts
Container mode now available in the advanced spawner
- 01 July 2025
We’re excited to announce that container mode is now enabled in our advanced JupyterHub spawner.
Container mode allows users to choose from a list of pre-defined container images when starting a Jupyter session. Each image is tailored for specific workflows (e.g. data science, coding).
HSM tools June 2025 updates
- 26 June 2025
New versions of the slk_helpers (1.16.5) and of the slk_wrappers (2.4.0) are available which contain several new features and bugfixes. The major changes focuses on improvements of the retrieval workflow. Additionally, an experimental version of a command called slk_helpers resource_features is released which can print various resource details such as caching state, size and various time stamps in a CSV-like way. An exact list of changes since the last officially announced release can be found in the changelog blog entry.
In Februar, we announced the new recall and retrieval scripts called recall watcher and retrieve watcher. Apart from fixing a few bugs, we simplified the process of starting and stopping these scripts. To do so, the slk_helpers received three new commands:
Changelog slk_helpers v1.16.5
- 26 June 2025
Update from slk_helpers v1.13.2 to v1.16.5
see here for changes from slk_helpers v1.12.0 to 1.13.2
HSM tools February 2025 updates
- 03 February 2025
New versions of the slk_helpers (1.13.2), of pyslk (2.2.0) and of the slk_wrappers (2.0.1) are available which contain several new features and bugfixes. The major changes and improvements are presented here. Details on minor changes can be found in the slk_helpers changelog and the pyslk changelog (pyslk changelog).
We’re excited to announce new commands and scripts designed to simplify data retrieval, following a thorough testing phase with multiple users. We’re aware that large-scale usage could reveal unforeseen challenges, particularly with StrongLink. Therefore, we’ll be actively monitoring system performance and encourage users to provide feedback. This experimental workflow is a collaborative effort, and we’re committed to making it the best possible solution. We’re also working on additional tools to further enhance data transfer to and from the tape archive. If necessary, based on performance data and user feedback, we may adjust or even temporarily deactivate this experimental workflow to ensure system stability and optimal performance.
Changelog slk_helpers v1.13.2
- 03 February 2025
Update from slk_helpers v1.12.10 to 1.13.2
see here for changes from slk_helpers v1.10.2 to 1.12.10
How to get more memory for my Slurm job
- 30 September 2024
The amount of memory specified on the Levante configuration page for different node types refers to the total physical memory installed in a node. Since some memory is reserved for the needs of the operating system and the memory-based local file system (e.g. /tmp, /usr), the amount of memory actually available for job execution is less than the total physical memory of a node.
The table below provides numbers for the preset amounts of
physical memory (RealMemory), memory reserved for the system
(MemSpecLimit) and memory available for job execution (which is the
difference between RealMemory and MemSpecLimit) for three
Levante node variants:
Slurm-managed cronjobs
- 06 August 2024
To execute recurring batch jobs at specified dates, times, or intervals, you can use the Slurm scrontab tool. It provides a reliable alternative to the traditionally used cron utility to automate periodic tasks on Levante.
To define the recurring jobs, Slurm uses a configuration file,
so-called crontab, which is handled using the scrontab
command. The scrontab command with the -e option invokes an
editing session, so you can create or modify a crontab:
HSM module cleanup April 2024
- 25 April 2024
On 30 April 2024 many modules of old slk and slk_helpers version will be removed from Levante.
modules which will be removed:
Changelog slk_helpers v1.12.10
- 25 April 2024
Update from slk_helpers v1.10.2 to 1.12.10
see here for changes from slk_helpers v1.9.7 to v1.10.2
HSM: check storage location of files
- 11 April 2024
From time to time connection issues between StrongLink and one of the tape libraries occur. If the retrieval of a file fails repeatedly in such a situation, then it is useful to be able to check whether the file is stored on a tape in the affected library. For this purpose we provide the commands slk_helpers resource_tape and slk_helpers tape_library.
Example:
Keeping disk usage in /home under control
- 11 January 2024
Sufficient free storage space in your /home directory is required
to run many software packages successfully. This is because the home
directory is used to store various small files during program
execution, such as configuration files, log files, lock files, named
pipes, and Unix sockets. If these files cannot be created or written,
an exhausted home quota may lead to a wide range of seemingly
unrelated error messages and issues. One example is the failure to
start a JupyterHub session. Regularly monitoring disk space usage in
your home directory is therefore essential for the smooth use of the
Levante HPC system.
You can check disk usage and limits for your /home directory on
Levante using the following command:
Changelog slk_helpers v1.10.2
- 01 December 2023
Update from slk_helpers v1.9.7 to v1.10.2
see here for changes from slk_helpers v1.9.5 to v1.9.9
Changelog slk_helpers v1.9.9
- 17 October 2023
Update from slk_helpers v1.9.7 to v1.9.9
see here for changes from slk_helpers v1.9.3 to v1.9.5
HSM News for Oct 2023
- 09 October 2023
will be installed in module python3/2023.01-gcc-11.2.0 on Oct 17th
new function pyslk.construct_dst_from_src() which accepts source file(s) and a destination root path is input and constructs the destination path of each source file if it was archived by slk archive
Changes in pyslk 1.9
- 25 August 2023
updated: 2023-09-18 (removed note)
A major structural change was implemented in pyslk version 1.9.0 compared to older versions. The implementation of this change did start in version 1.7.0 but most parts where implemented in 1.9.0. All functions which are meant to be used by end-users, can be used without specifying the module’s name: pyslk.example_function instead of pyslk.module_name.example_function.
Changelog slk_helpers v1.9.5
- 14 July 2023
Update from slk_helpers v1.9.3 to v1.9.5
see here for changes from slk_helpers v1.9.0 to v1.9.3
Changelog slk_helpers v1.9.3
- 06 July 2023
Update from slk_helpers v1.9.0 to v1.9.3
see here for changes from slk_helpers v1.8.10 to v1.9.0
Changelog slk_helpers v1.9.0
- 22 May 2023
Update from slk_helpers v1.8.10 to v1.9.0
see here for changes from slk_helpers v1.8.2 to v1.8.10
Important news for slk usage
- 08 May 2023
This content is outdated. Please check out our current recommendations in the documentation.
Please do not retrieve files from more than 10 tapes with one call of slk retrieve / recall. Using more tapes in one call of slk retrieve might slow down the whole StrongLink System considerably.
Changelog slk_helpers v1.8.10
- 08 May 2023
Update from slk_helpers v1.8.2 to v1.8.10
see here for changes from slk_helpers v1.7.4 to v1.8.2
Changelog slk_helpers v1.8.7
- 24 April 2023
Update from slk_helpers v1.8.2 to v1.8.7
see here for changes from slk_helpers v1.7.4 to v1.7.4
OpenSSH Certificate Authentication
- 11 April 2023
It is very convenient to allocate part of a node ore even a full node for interactive work on Levante. We describe how to do this in our main documentation.
If you always use a login node of Levante to log into the allocated node, then you won’t have any problems with host keys. However, if you use a login node as a jump host for loging into the allocated node from your local machine, then you may see a warning.
Changelog slk_helpers v1.8.2
- 21 March 2023
Update from slk_helpers v1.7.4 to v1.8.2
see here for changes from slk_helpers v1.7.1 to v1.7.4
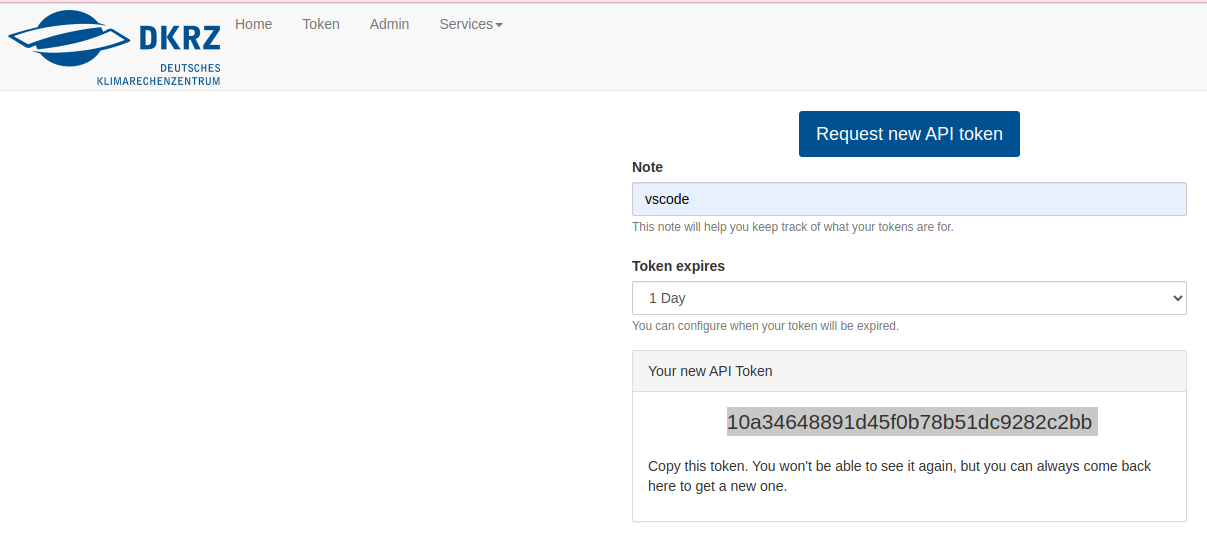
Set up Remote Developement/Debugging
- 24 February 2023
Some workarounds related to remote development/debugging on Levante. These workarounds are not tested on all available remote tools but often specific to a certain IDE. We encourage you to test on your favorite IDE and report issues to support@dkrz.de.
Tested on VSCode
Changelog slk_helpers v1.7.4
- 10 February 2023
Update from slk_helpers v1.7.1 to v1.7.4
see here for changes from slk_helpers v1.6.0 to v1.7.1
Changelog slk v3.3.83
- 31 January 2023
Changes from slk v3.3.81 to v3.3.83
see here for changes from slk v3.3.76 to v3.3.81
E-Mail notification when login token due to expire
- 24 January 2023
As suggested by the DKRZ-Usergroup there is now the possibility to remind users when their token is due to expire. We provide a SLURM script for this purpose. The 30-day validity of the login token remains unchanged. Details are given in Reminder login token expires.
How can I log into levante, change my password and login shell?
- 24 January 2023
To access Levante login nodes via ssh with X11 forwarding, use:
For macOS we recommend to use -Y instead of the -X option.
I want to add my own packages to Python or R but they won’t compile
- 24 January 2023
Python and R, among other scripting languages, allow users to create customized environments including their own set of packages.
For Python you use virtualenv or conda, R can also add locally installed packages.
Which Compiler and MPI library should I use?
- 24 January 2023
For model simulations in production mode we recommend to use Intel compilers and Open MPI:
Do not forget to consult the recommended environment settings and adjust your run script accordingly. Without these settings applications can run unexpectedly slowly.
How do I log into the same login node I used before
- 24 January 2023
levante.dkrz.de maps to a whole group of nodes to distribute the load:
All login nodes share the same file system so most of the time you do
not have to care which node you are on. However, there are reasons why
you may want to connect to a specific node (for example, to reattach
to a running tmux session). You first have to find out
on which node you are. This may be indicated in your prompt or you can
also use hostname for this purpose:
Changelog slk_helpers v1.7.1
- 16 January 2023
Please use slk_helpers version 1.7.2 (module load slk_helpers/1.7.2) instead of 1.7.1 because one minor issue was fixed in 1.7.2 (detailed changelog). There will be no extra blog entry for slk_helpers 1.7.2.
Update from slk_helpers v1.6.0 to v1.7.1
Changelog slk v3.3.81
- 16 January 2023
Changes from slk v3.3.76 to v3.3.81
slk retrieve and slk recall print the id of the StrongLink-internal tape-recall job
Changelog slk_helpers v1.6.0
- 08 December 2022
Update from slk_helpers v1.5.8 to v1.6.0
see here for changes from slk_helpers v1.5.7 to v1.5.7
Changelog slk v3.3.76
- 08 December 2022
Changes from slk v3.3.67 to v3.3.76
Changlog updated on 2022-12-08
Changelog slk_helpers v1.5.8
- 06 December 2022
Update from slk_helpers v1.5.7 to v1.5.8
see here for changes from slk_helpers v1.2.x to v1.5.7
Changelog slk v3.3.75
- 06 December 2022
Changes from slk v3.3.67 to v3.3.75
Changlog updated on 2022-12-06
Changelog slk v3.3.67
- 21 October 2022
Changes from slk v3.3.21 to v3.3.67
Changlog updated on 2022-10-21 (changes in slk chmod extended)
How big are my files?
- 21 October 2022
Our server luv shows you how much storage space your project is using and also how much each individual project member is contributing. For technical reasons, we can only show the apparent size (see below) of a user’s files. For the entire project, however, we show the actually occupied disk space. We are not happy about this inconsistency but for now, we have to live with it.
Here we try to explain the difference between the two ways to measure the size of files.
Changelog slk_helpers v1.5.7
- 19 September 2022
Update from slk_helpers v1.2.x to v1.5.7
Please have a look here for a detailed description of the new features and here for an incremental changelog.
Can I get my compute time back?
- 22 August 2022
Who wouldn’t want to use all of their node hours on Levante in the most productive way? After all, this is how we present our project in the proposal. Everything will go according to plan. What could go wrong? In fact, a lot, so can I get the time back in that case? Here is an incomplete list of things we often hear.
I found a bug in my model and now I have to run all experiments again.
Using tmux for persistent ssh connections
- 02 August 2022
Tmux allows you to keep a shell session active when closing your ssh connection. So, when you close your laptop to change a room, you don’t lose the current state of your command line tools. It has many more useful features.
However, you need to remember the login node you used to start tmux, and X11 applications (e.g. ncview) will not survive the disconnect. emacs will survive in command line mode (module load emacs ; emacs -nw).
The following examples will assume that you have prescribed your user name and allowed (trusted) X11 forwarding for dkrz.de machines in your ~/.ssh/config
Basemap on levante
- 14 June 2022
Basemap has reached end-of-life and we won’t install basemap system wide (python 3 module) but you can easily install it into a personal conda environment like this
On Levante:
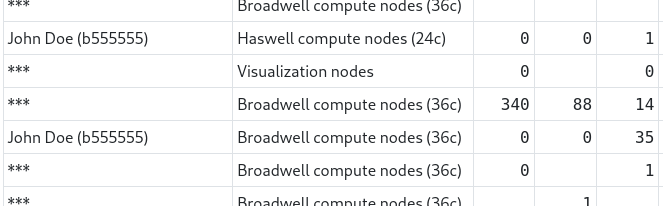
API for Accounting Data
- 09 June 2022
As a project admin or even as a normal project user you may look from time to time into accounting data for resources we provide (Levante, archive, etc.).
For each project you participate in, you can find a table on https://luv.dkrz.de like the one shown below. Usually you only see your own entries. Other user’s names are hidden.
How to build ICON on Levante
- 20 May 2022
The current ICON release 2.6.4 has no setup for building and running on the new HPC system levante
There are multiple options to get an ICON binary and run it:
Using Spyder on levante
- 26 April 2022
The Python IDE Spyder is hidden in the python3 module and needs additional libraries from spack to start.
Load the missing libraries via spack and load python3 (which contains spyder):
libGL.so.1 missing
- 22 April 2022
Update 2022-10-17: This problem should be fixed with our current software stack. The workaround is not required any longer.
When trying to start a gui application like gvim, you get an error message:
Data Migration Mistral to Levante
- 04 March 2022
So that not every user or every project has to copy its data from Mistral to Levante, DKRZ will take over this in a coordinated manner. In this way, the bandwidth between the systems can be better utilised.
We will only copy data located in /work - and only for projects that have
resources granted on the Levante system.
Bus error in jobs
- 11 February 2022
Update 2022-06-14: The problem was solved by an update of the Lustre-client by our storage vendor. The workaround described below should no longer be necessary. If one of your jobs runs into a bus error, please let us know.
When running jobs on Levante, these sometimes fail with a Bus error, similar to the example below:
DKRZ CDP Updates Feb 22
- 28 January 2022
We proudly 🥳 announce that the CDP is extended by new sets of CMIP6 data primarily published at DKRZ.
The ensemble set of simulations from the ESM MPI-ESM1-2-LR is now completed with additional 130 Simulations. For each of the following experiments, 30 Simuluations form an ensemble of different realizations with varying initial conditions:
About data on curvilinear or rotated regional grids
- 29 November 2021
2D Climate data can be sampled using different grid types and topologies, which might make a difference when it comes to data analysis and visualization. As the grid lines of regular or rectilinear grids are aligned with the axes of the geopgraphical lat-lon coordinate system, these model grids are relatively easy to deal with. A common, but more complex case is that of a curvilinear or a rotated (regional) grid. In this blog article we want to illuminate this case a bit; we describe how to identify a curvilinear grid, and we demonstrate how to visualize the data using the “normal” cylindric equidistant map projection.
Data can not only be stored in different file formats (e.g. netCDF, GRIB), but also in different data structures. Besides its spatial dimension (e.g. 1D, 2D, 3D), we need to have a closer look at the grid and the topology used. As the time dependency of the data is encoded as the time dimension, a variable might be called a 3D variable although the spatial grid is only 2D.

DKRZ CDP Updates Nov 21
- 25 November 2021
including the new ICON-ESM-LR model primarily published at DKRZ.
A first ensemble set of simulations from the ESM ICON-ESM-LR for the DECK experiments is available including the experiments
How to install R packages in different locations?
- 25 October 2021
The default location for R packages is not writable and you can not install new packages. On demand we install new packages system-wide and for all users. However, it possible to install packages in different locations than root and here are the steps:
create a directory in $HOME e.g. ~/R/libs
JupyterDash on Jupyterhub @ DKRZ
- 24 October 2021
As of Dash v2.11, Jupyter support is built into the main Dash package, which is installed in jupyterhub. You don’t need the jupyter_dash anymore. See https://dash.plotly.com/dash-in-jupyter for usage details.
This content is based on this notebook.
DKRZ CDP Updates July 21
- 02 July 2021
We proudly 🥳 announce that the CDP is extended by new sets of CMIP6 data primarily published at DKRZ. We also published new versions of corrected variables for the MPI-ESM1-2 Earth System Models.
The ensemble set of simulations from the ESM MPI-ESM1-2-HR for the dcppA-hindcast experiment is completed by another 5 realizations (8.5TB). In total, this set consists of about 10 realizations for 60 initialization years in the interval from 1960-2019 resulting in 595 realizations and 31 TB. For each realization, about 100 variables are available for a simulation time of about 10 years.
DKRZ CMIP Data Pool
- 23 June 2021
We proudly announce new publications of model simulations when we publish them at our DKRZ ESGF node. We also keep you updated about the status and the services around the CMIP Data Pool. Find extensive documentions under this link.
How to install jupyter kernel for Matlab
- 10 June 2021
Fixed broken link in Matlab release section.
In this tutorial, we will describe i) the steps to create a kernel for Matlab and ii) get the matlab_kernel working in Jupyterhub on Levante.

How to re-enable the deprecated python kernels?
- 16 May 2021
Within the maintenance of Monday, May 15th, we will perform updates in our python installations (please see the details here).
Since the jupyterhub kernels are based on modules, the deprecated kernels will no longer be available as default kernels in jupyter notebooks/labs.
Requested MovieWriter (ffmpeg) not available
- 06 May 2021
Requested MovieWriter (ffmpeg) not available
conda env with ffmpeg and ipykernel
Create a kernel from your own Julia installation
- 23 March 2021
We already provide a kernel for Julia based on the module julia/1.7.0.
In order to use it, you only need to install ÌJulia:
Python environment locations
- 04 March 2021
Kernels are based on python environments created with conda,
virtualenv or other package manager. In some cases, the size of the
environment can tremendously grow depending on the installed packages.
The default location for python files is the $HOME directory. In
this case, it will quickly fill your quota. In order to avoid this, we
suggest that you create/store python files in other directories of the
filesystem on Levante.
The following are two alternative locations where you can create your Python environment:
Dask jobqueue on Levante
- 16 November 2020
According to the official Web site, Dask jobqueue can be used to
deploy Dask on job queuing systems like PBS, Slurm, MOAB, SGE,
LSF, and HTCondor. Since the queuing system on Levante is Slurm, we are
going to show how to start a Dask cluster there. The idea is simple as
described here. The difference is that the workers can be distributed
through multiple nodes from the same partition. Using Dask jobqueue you can launch
Dask cluster/workers as a Slurm jobs. In this case, Jupyterhub will play an interface role and the Dask
can use more than the allocated resources to your jupyterhub session
(profiles).
Load the required clients
Enable NCL Kernel in Jupyterhub
- 05 November 2020
Can’t use NCL (Python) as kernel in Jupyter
This tutorial won’t work
FileNotFoundError: [Errno 2] No such file or directory
- 07 October 2020
See Wrapper packages here.
you:
Jupyterhub log file
- 25 September 2020
Each Jupyter notebook is running as a SLUM job on Levante. By default,
stdout and stderr of the SLURM batch job that is spawned by
Jupyterhub is written to your HOME directory on the HPC system. In
order to make it simple to locate the log file:
if you use the preset options form: the log file is named
jupyterhub_slurmspawner_preset_<id>.log.
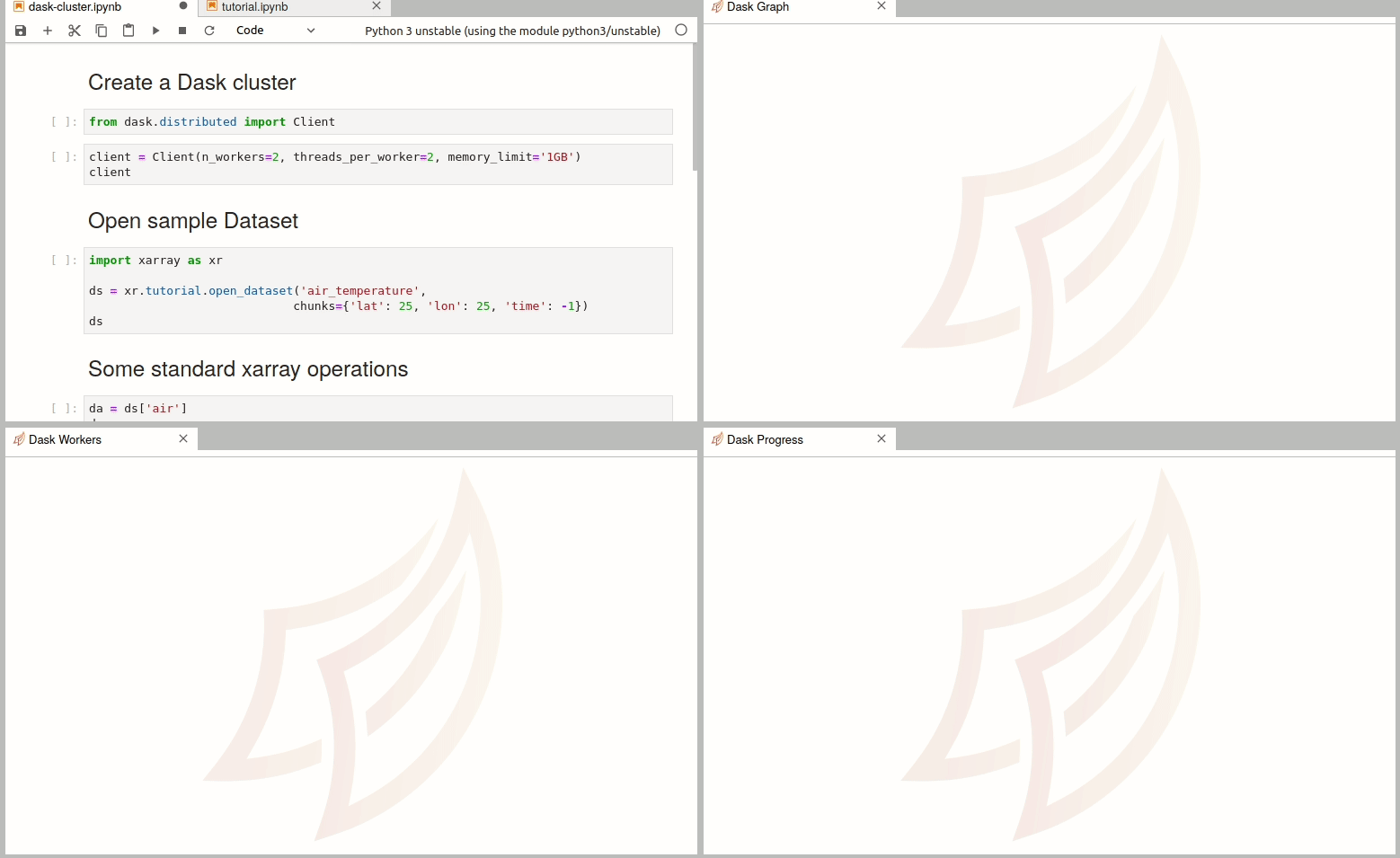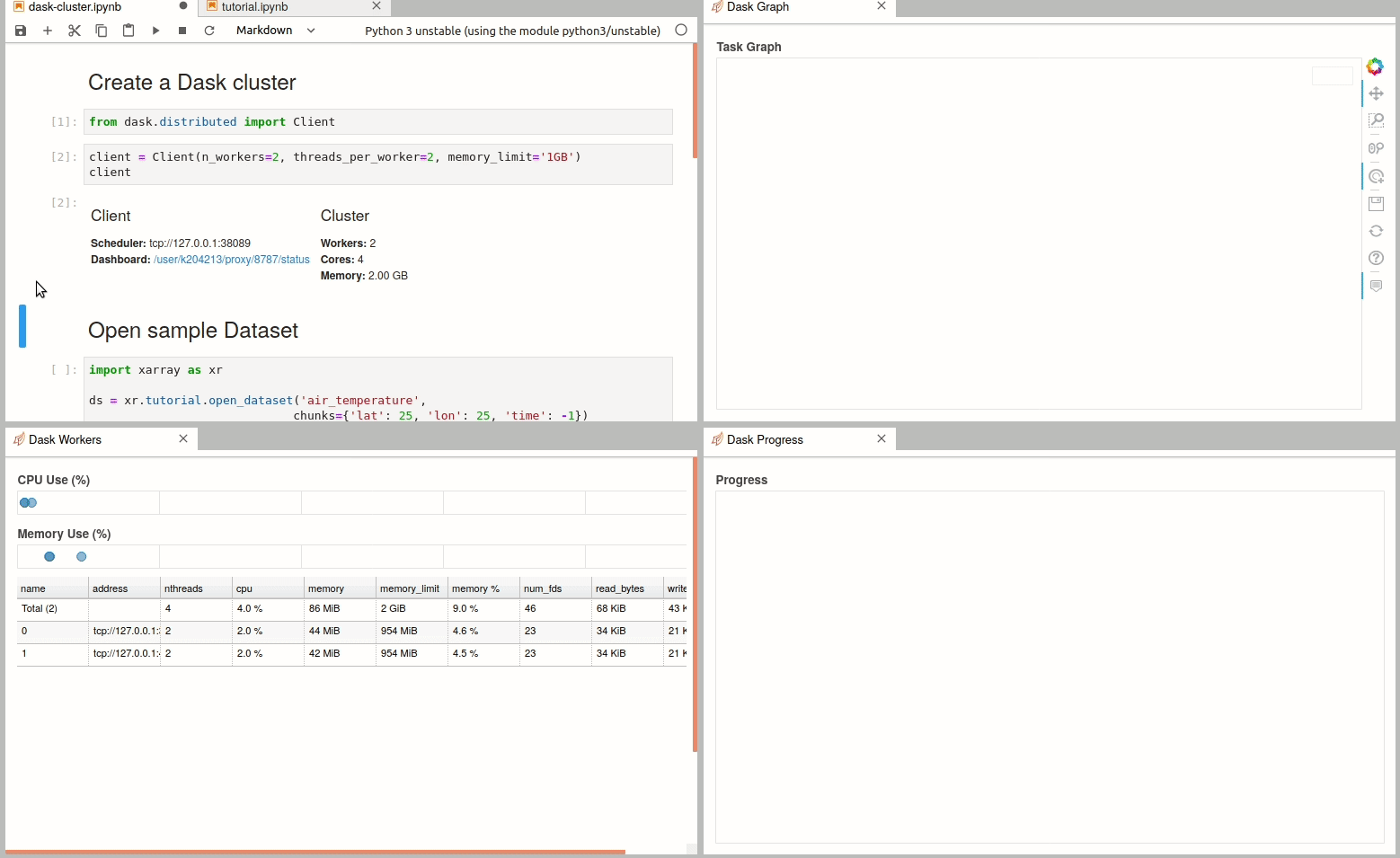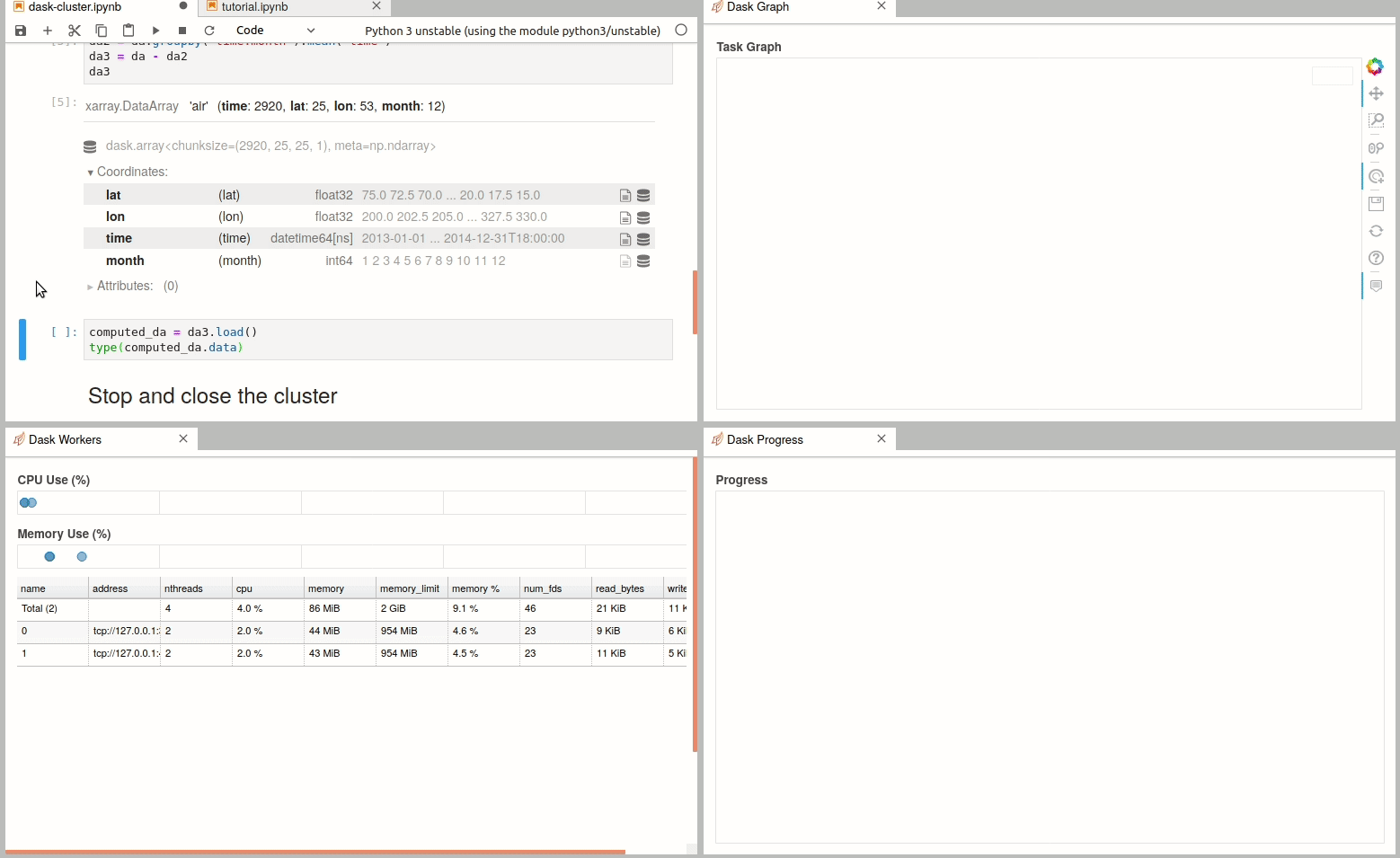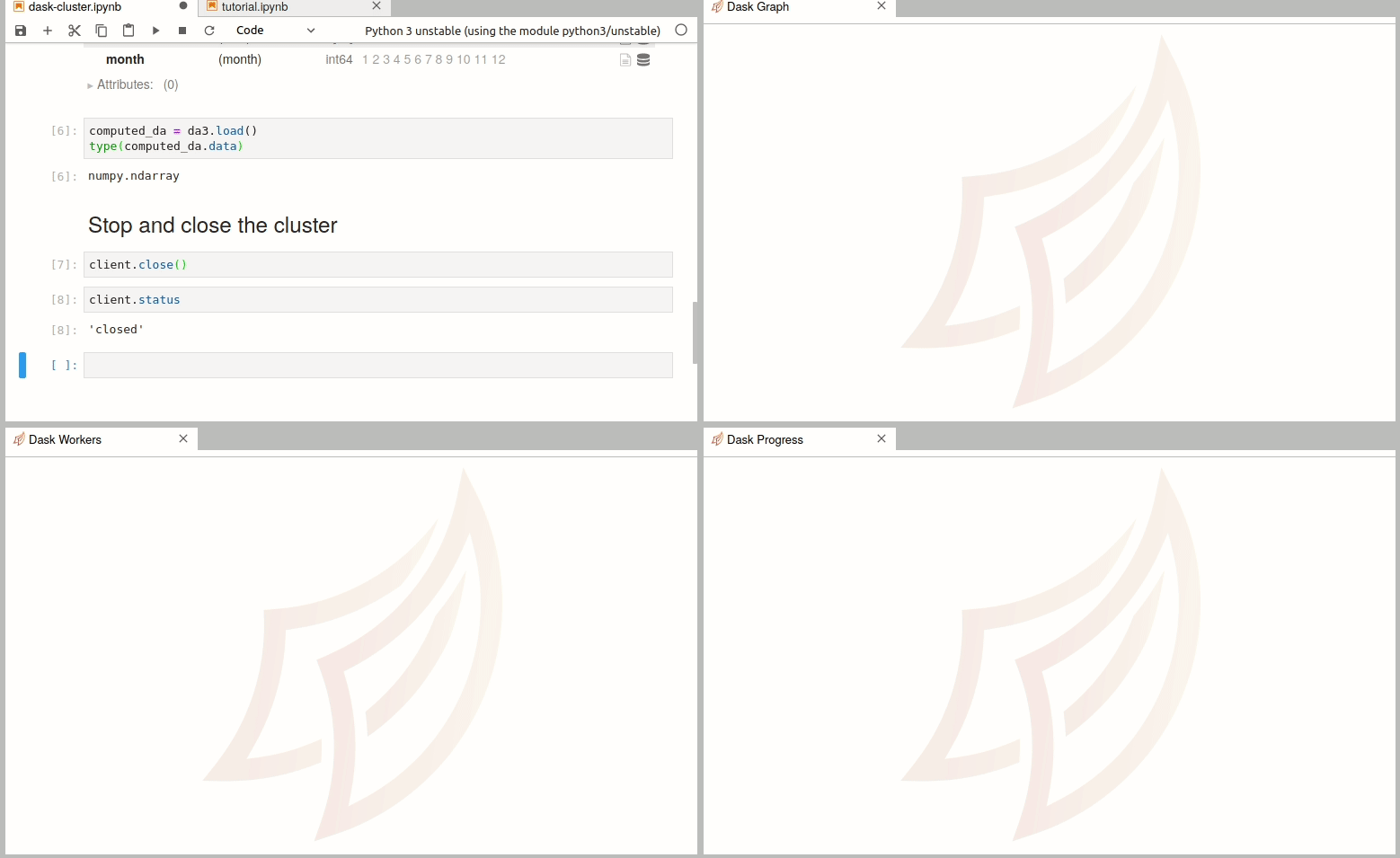
Simple Dask clusters in Jupyterhub
- 18 September 2020
There are multiple ways to create a dask cluster, the following is only an example. Please consult the official documentation. The Dask library is installed and can be found in any of the python3 kernels in jupyterhub. Of course, you can use your own python environment.
The simplest way to create a Dask cluster is to use the distributed module:
DKRZ Tech Talks
- 03 September 2020
It is our great pleasure to introduce the DKRZ Tech Talks. In this series of virtual talks we will present services of DKRZ and provide a forum for questions and answers. They will cover technical aspects of the use of our compute systems as well as procedures such as compute time applications and different teams relevant to DKRZ such as our machine learning specialists. The talks will be recorded and uploaded afterwards for further reference.
Go here for more information.
New Jupyterhub server at DKRZ
- 03 September 2020
On August 20th, 2020 we deployed a new Jupyterhub server at the DKRZ. The new release has various new features that enhance the user experience.
How to prevent interuptions of ssh connections to DKRZ systems?
- 23 October 2019
If your ssh connections to login nodes are interrupted after short
periods without any keyboard activitiy and you get an error message
containing the string “broken pipe”, try to set the
ServerAliveInterval parameter appropriately.
On Linux and macOS systems with the OpenSSH implementation there is essentially two methods to adjust this client setting. First, it can be set as a command-line option to ssh:
How do I share files with members of another project?
- 17 September 2019
You can use ACLs to achieve this. As a member of project group ax0001, you would have to create a directory in your project’s work for example
It could be any other place on Lustre file systems where you have write access. Then you grant project bx0002 permissions to this directory
Why do I receive .Xauthority file error messages?
- 08 July 2019
When you open a new terminal session with X forwarding turned on (ssh -X ...),
the .Xauthority file in your home directory gets updated by the xauth program.
This file is used to keep X authentication keys in order to prevent unauthorized
connections to your local display.
Sometimes, the .Xauthority file cannot be updated due to the
temporary issues with the Lustre file system, where your home
directory is located, and you might experience an error message like:
Python Matplotlib fails with “QXcbConnection: Could not connect to display”
- 18 September 2018
Matplotlib is useful for interactive 2D plotting and also for batch production of plots inside a job. The default behavior is to do interactive plotting which requires the package to open a window on your display. For this purpose you have to log into mistral with X11 forwarding enabled.
If you run matplotlib in a jobscript where you just want to create files of your plots, you have to tell matplotlib to use a non-interactive backend. See matplotlib’s documentation how to do that and which backends are available. Here is how to select the Agg backend (raster graphics png) inside your script. Add to the top of your imports
How can I avoid core files if my program crashes
- 30 May 2018
Core files can be very helpful when debugging a problem but they also take a long time to get written for large parallel programs. The following command will limit the core size to zero, i.e. no core files will be written:
The effect of the above command call can be checked with:
Why does my job wait so long before being executed? or: Why is my job being overtaken by other jobs in the queue?
- 19 June 2017
There are several possible reasons for to be queued for a long time and/or to be overtaken …
… later submitted jobs with a higher priority (usually these have used less of their share then your job).
When will my SLURM job start?
- 19 June 2017
The SLURM squeue command with the options - -start and -j provides an estimate for the job start time, for example:
How to use environment modules in batch scripts
- 19 June 2017
module is a shell function which modifies shell environment after
loading or unloading a module file. If you are using different shells
as login shell and for job batch scripts (e.g. tcsh as login shell
and your job scripts start with #!/bin/bash), you need to add an
appropriate source command in your script before any invocation of
the module function (otherwise the module: command not found.
error message will result and the shell environment won’t be modified
as intended):
How to use SSHFS to mount remote lustre filesystem over SSH
- 19 June 2017
In order to interact with directories and files located on the lustre filesystem, users can mount the remote filesystem via SSHFS (SSH Filesystem) over a normal ssh connection.
SSHFS is Linux based software that needs to be installed on your local computer. On Ubuntu and Debian based systems it can be installed through apt-get. On Mac OSX you can install SHFS - you will need to download FUSE and SSHFS from the osxfuse site. On Windows you will need to grab the latest win-sshfs package from the google code repository or use an alternative approach like WinSCP.
How to set the default Slurm project account
- 19 June 2017
Specification of the project account (via option -A or
--account) is necessary to submit a job or make a job allocation,
otherwise your request will be rejected. To set the default project
account you can use the following SLURM input environment variables
SLURM_ACCOUNT - interpreted by srun command
How to improve interactive performance of MATLAB
- 19 June 2017
When using ssh X11-Forwarding (options -X or -Y), matlab can
be slow to start and also exhibit slow response to interactive use. This
is because X11 sends many small packets over the network, often
awaiting a response before continuing. This interacts unfavorably with
medium or even higher latency connections, i.e. WiFi.
A way to eliminate this issue is to use dedicated resources and to
start a remote desktop session that does not suffer from network
latencies in the same manner. This approach requires a VNC client
vncviewer installed on your local machine. A widely used VNC
client is TurboVNC.
How to display the batch script for a running job
- 19 June 2017
Once your batch job started execution (i.e. is in RUNNING state)
your job script is copied to the slurm admin nodes and kept until the
job finalizes - this prevents problems that might occur if the job
script gets modified while the job is running. As a side-effect you
can delete the job script without interfering with the execution of
the job.
If you accidentally removed or modified the job script of a running job, you can use the following command to query for the script that is actually used for executing the job:
How to Write a shell alias or function for quick login to a node managed by SLURM
- 19 June 2017
For tasks better run in a dedicated but interactive fashion, it might be advantageous to save the repeating pattern of reserving resources and starting a new associated shell in an alias or function, as explained below.
If you use bash as default shell you can place the following alias
definition in your ~/.bashrc file and source this file in the
~/.bash_profile or in the ~/.profile file:
How can I see on which nodes my job was running?
- 19 June 2017
Yon can use the SLURM sacct command with the following options:
How can I run a short MPI job using up to 4 nodes?
- 19 June 2017
You can use SLURM Quality of Service (QOS) express by inserting the following line into your job script:
or using the option –qos with the sbatch command:
How can I get a stack trace if my program crashes?
- 19 June 2017
The classical approach to find the location where your program crashed is to run it in a debugger or inspect a core file with the debugger. A quick way to get the stack trace without the need for a debugger is to compile your program with the following options:
In case of segment violation during execution of the program, detailed information on the location of the problem (call stack trace with routine names and line numbers) will be provided:
How can I choose which account to use, if I am subscribed to more than one project?
- 19 June 2017
Just insert the following line into your job script:
There is no default project account.
How can I check my disk space usage?
- 19 June 2017
Your individual disk space usage in HOME and SCRATCH as well as the quota state of your projects can be checked using the commands listed in File Systems. An additional overview is provided DKRZ online portal. The numbers there are updated daily.
(updated 2023-07-26)
How can I access my Lustre data from outside DKRZ/ZMAW?
- 19 June 2017
For data transfer you can use either sftp:
or rsync command:
Can I run cron jobs on HPC login nodes?
- 19 June 2017
Update 2024-10-01: This procedure has been superseded by the Slurm scrontab feature, now available on Levante.
For system administration reasons users are not allowed to shedule and
execute periodic jobs on DKRZ HPC systems using the cron utility. Our
recommendation is to use the functionality provided by the workload
manager Slurm for this purpose. With the option --begin of the
sbatch command you can postpone the execution of your jobs until
the specified time. For example, to run a job every day after 12pm
you can use the following job script re-submitting itself at the
beginning of the execution:
Is a FTP client available on Levante?
- 18 June 2017
LFTP is installed on Levante for download and upload of files from/to an external server via File Transfer Protocol (FTP):
The user name for authentication can be provided via option -u or
--user.