Overview#
There are a few points you should be aware of when working with Jupyter Notebooks on the jupyterhub server:
Sessions are persistent. If you close the browser tab without stopping the server before, you can revisit the jupyterhub site and carry on working
Closing browser’s tab or log-in out will not stop your session, your session will continue consuming resources (see next point)
- It is preferable to stop the session when you finish. This depends on the jupyter interface:
JupyterLab:
File->Hub Control Panelthenstop.Classical Jupyter:
Control Paneland thenstop
Currently, in container mode we extended the top right bar with a Hub Control Panel button.
Note
If you are new to DKRZ and want to access our JupyterHub, please consult the Quick Start page.
Note
If the batch queue is filled with waiting jobs, it might take some time to start the notebook server. There is an internal timelimit (300 sec) specified until which the resources should be ready. If not the spawner will reject and ask you to start again (maybe with reduced resources specified).
Introductory presentation#
On September 1st, 2020, we deployed the first customized release of our Jupyterhub server.
It was presented in the DKRZ Tech Talks.
You can view the talk on Youtube or download the slides.
Since the initial release, we’ve made numerous improvements to the service that can be found in the Changelog.
Architecture#

Interface#
Jupyterlab is the default interface. However, you can switch to the classic notebook by adding /lab before /tree in the URL. To return to JupyterLab, simply reverse this change.
/user/<username>/<server-name>/lab/tree/ -> /user/<username>/<server-name>/tree/
If you use the advanced spawner, you can select the interface from the list of UIs before starting the session.
Issues with Jupyterhub?#
If you have issues while spawning servers or when working on your notebook, we suggest that you first try one of the following steps:
JupyterHub provides clear error messages for invalid inputs, access denials, and issues related to SLURM (JobID and REASON).
|

|
Check the log file if you see a waiting to connect mesage. By default,
stdoutandstderrof the SLURM batch job that is spawned by Jupyterhub is written to yourHOMEdirectory on the HPC system. In order to make it simple to locate the log file:if you use the
presetoptions form: the log file is namedjupyterhub_slurmspawner_preset_<id>.log.if you use the
advancedoptions form: the log file is namedjupyterhub_slurmspawner_advanced_<id>.log. You can even change the name of the output log file (Log File Name).Log File Namealso allows you to change thePathof the output log file to a diffrent directory where you have write permissions.Example:
/path/to/your/scratch/name_of_your_logfile.
Try using the search bar in the docs or check out our blog — we’ve shared tutorials on some frequently encountered issues.
If the above steps do not help, send an e-mail to support@dkrz.de.
Known issues#
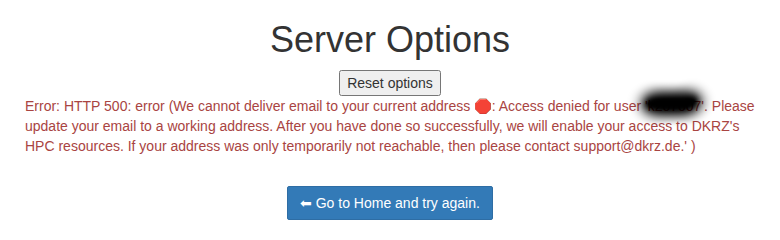
The following error message means that there is an issue with your EMail address. You need just to update it and contact support@dkrz.de to get access again.
Consult the documentation or the JupyterHub-related blog posts, which may contain solutions to the issue you are experiencing.” If the above steps do not help, send an e-mail to support@dkrz.de.