Data Science Services#
Individual project support#
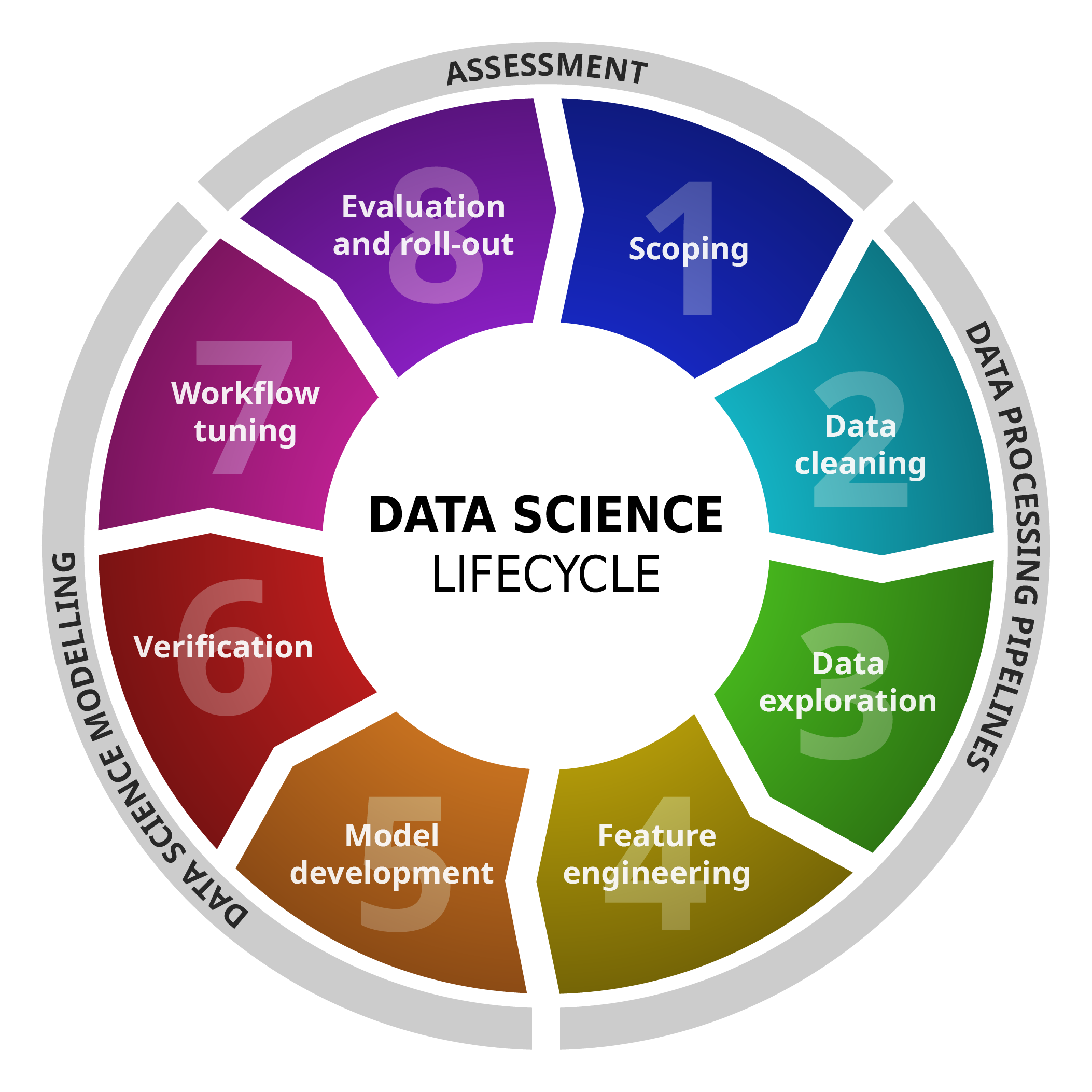
We offer individual support at no charge for data science projects at all development stages. As illustrated in the figure, these stages follow a cycle of definition of challenge and goals, setup and automation of pipelines for data processing, development and experimentation with a wide range of data science models, and finally evaluation and benchmarking of results. As users, you are always in the driving seat and determine which aspects will be covered through our support, how stages will be conducted collaboratively and how findings are to be used. Guiding principles for our support are co-development with you following your requirements, iterative agility and confidentiality.
A focus is on co-development of prototypes between DKRZ support and you. As requesting users, it is also up to you to specify data and challenges relevant from your perspective. Typical goals for us will be to empower you to make best use of the available tools and frameworks, lowering adoption barriers of data science methods through prototyping, consulting and training, and providing germination points from which you can commence successful research projects.
In addition to this general support setup, which applies to all activities, we also offer more specific support in two thematic areas:
Projects that integrate machine learning with Earth System Models, building ESM-ML hybrids that improve subscale process modelling or emulate costly submodels. Specific support includes ML prototyping on model output data, Python-Fortran software engineering aspects, model integration prototyping (e.g. with ICON) and performance optimization, and testing of ML-driven schemes against original baselines.
Projects that employ data science methods on Earth observation data relevant to Earth System science questions or on ESM output data in order to improve existing data product quality, derive new products, reduce errors or support the testing of new hypotheses on data. Specific support includes the setup, automation and delivery of data processing pipelines, development of data science models and their assessment, particularly for time series data and imagery (Sentinel, orthophotos).
If you are interested in benefitting from such support to your activities, please feel free to contact DKRZ user support (Help Desk) so we can have a first informal chat.
Technical best practices#
Machine Learning on Levante: How to get started with ML on Levante using Python and Jupyterhub
Tutorial for Machine Learning with Large Datasets: How to handle datasets that are too large to fit into memory by loading data lazily during training.
Guidance on methods#
ML projects can be very diverse in terms of the methods and technologies employed. The material referenced here gives general advice for you to get strted. If you have specific questions, please feel free to contact us.
Training course: Introduction to ML and data processing
How to get in touch?#
The Helmholtz AI team or Beratung.