ClusterCockpit#
ClusterCockpit is a framework for job-specific performance and power monitoring on distributed HPC clusters. The ClusterCockpit instance hosted at DKRZ provides job data for the past 180 days and detailed metric data for the past 90 days.
Note
ClusterCockpit is available at https://clustercockpit.dkrz.de for all DKRZ users who have access to Levante and who are allowed to submit batch jobs. Please contact support@dkrz.de if you encounter any problems with the login.
Job List#
The landing page after login displays the number of currently running and total jobs for your account. Following one of these links will open the job list.
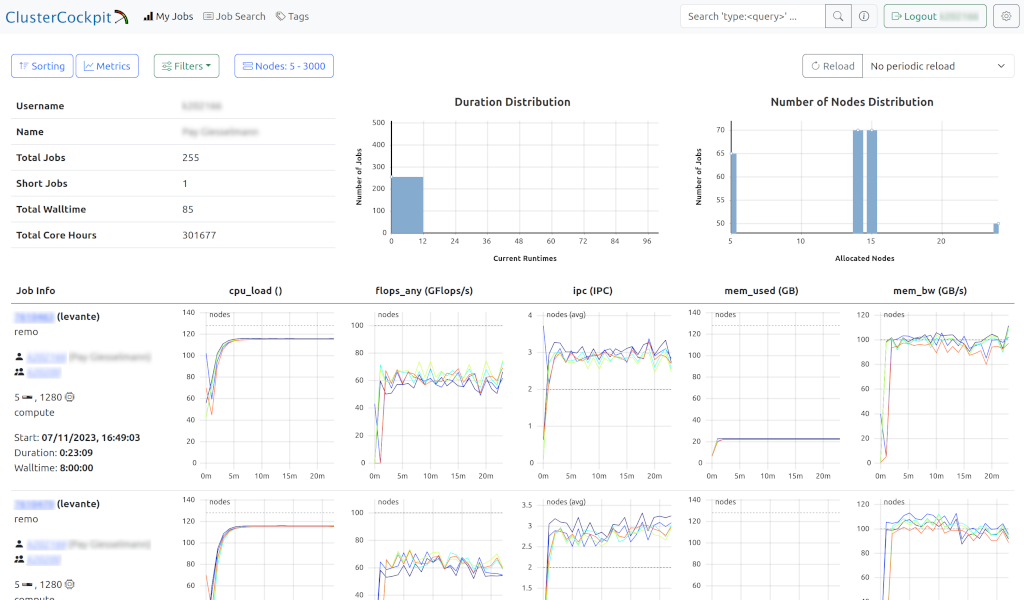
This overview page shows a summary of your batch jobs on levante, allowing to sort and filter based on jobs properties. The set of metrics displayed per job can be configured according to your preferences. New jobs are imported from SLURM every 5 minutes, completed jobs with less than 2 minutes runtime are skipped. A click on the Job-ID will open the job details page.
Job Details#
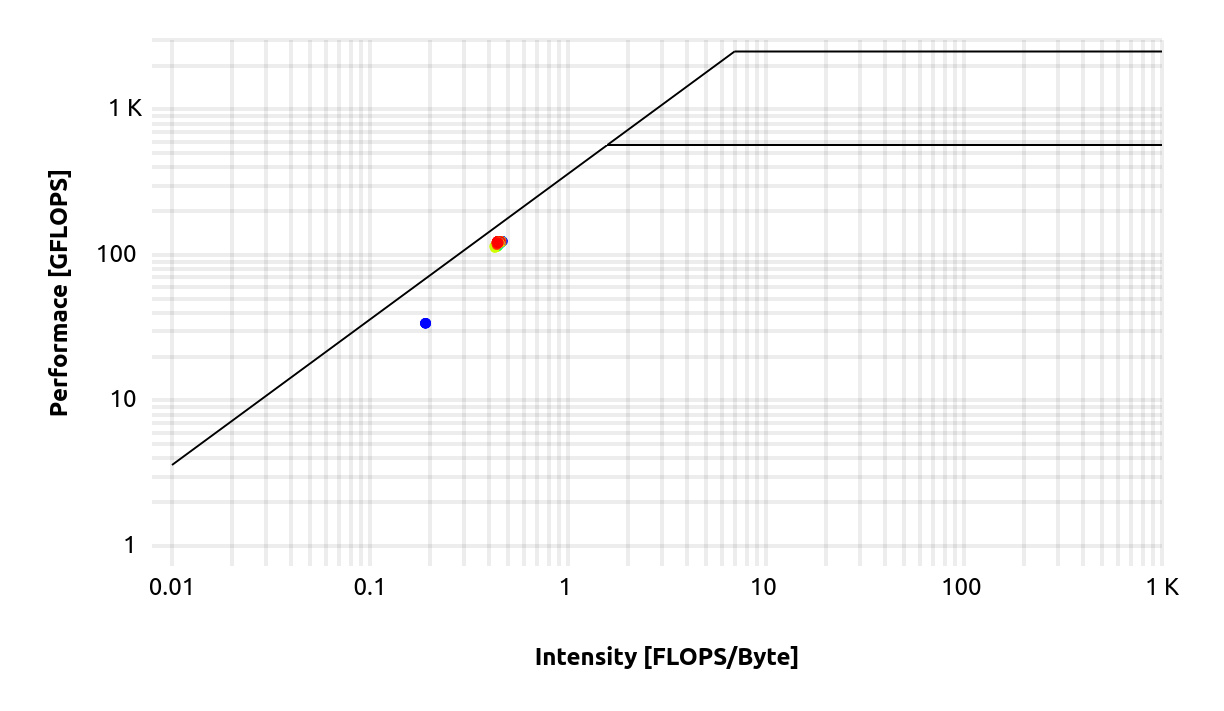
The job details view provides the job ressources summary, a job footprint in form of a radar plot and a roofline model. The example radar and roofline plot show an ICON R2B5 experiment using 16 compute nodes.
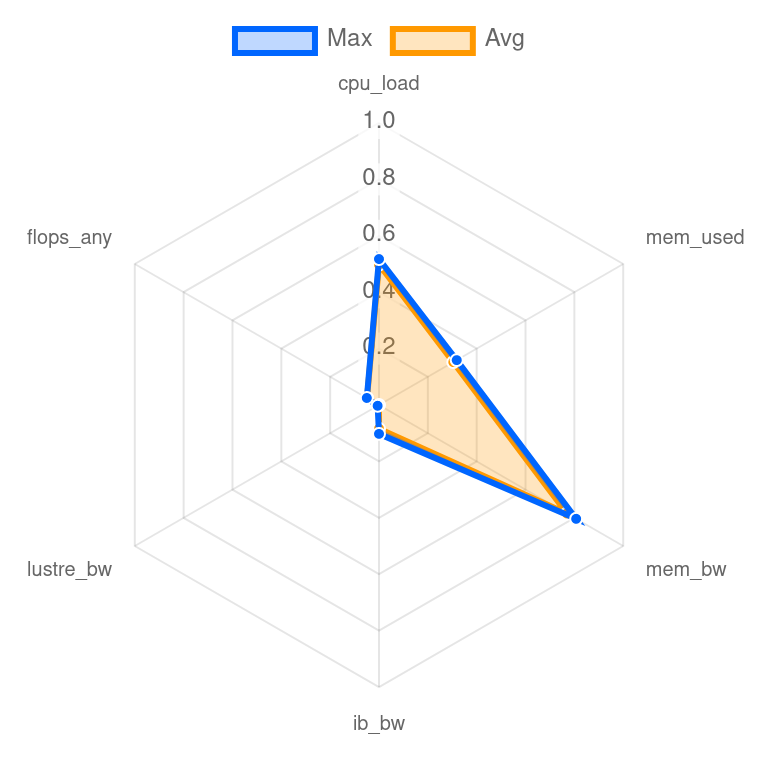
The radar plot puts the job performance into perspective with the machine limits. These limits on compute nodes of Levante are configured as follows:
Metric |
Description |
Limit |
|---|---|---|
cpu_load |
CPU load |
256 (SMT on) |
mem_used |
Memory usage |
256 GB |
mem_bw |
Memory bandwidth |
350 GB/s (STREAM) |
ib_bw |
Interconnect bandwidth |
100 GBit/s (full-duplex) |
lustre_bw |
Filesystem bandwidth |
100 GBit/s |
flops_any |
Floating point operations |
2500 GF/s (SIMD) |
Next the roofline model compares achieved performance to a “roofline” graph of peak data streaming bandwidth and peak FLOP/s capacity [1]. The different ceilings show scalar double precision performance (570 GF/s) and SIMD double precision performance (2500 GF/s) obtained from LIKWID bench. Points are colored from blue to red over the runtime with one minute resolution.
—